
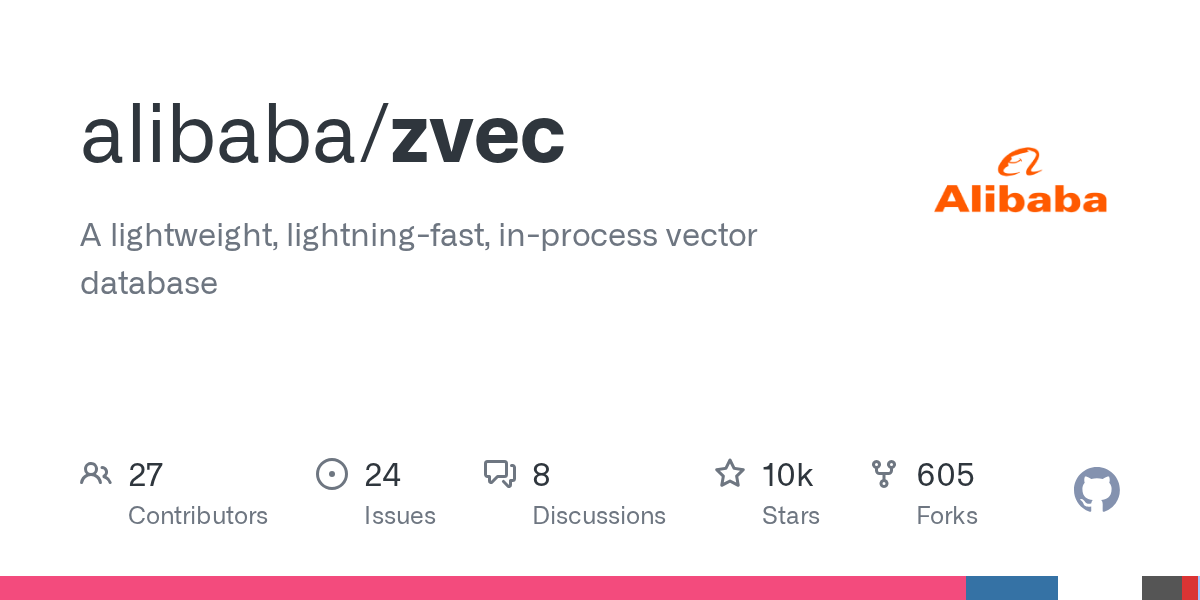
6月12日,阿里巴巴在 GitHub 上开源了 alibaba/zvec v0.5.0,一个号称”向量数据库领域的 SQLite”的特色项目——内嵌式(in-process)向量数据库,已获近 10,000 Star。
安装 & 一分钟上手
1. 安装
Python 3.10-3.14 环境,一行搞定:
pip install zvec
Node.js 版本:
npm install @zvec/zvec
Go 和 Rust 也有官方 SDK。
2. 创建集合
import zvec
# 定义集合 Schema
schema = zvec.CollectionSchema(
name="my_collection",
fields=[
zvec.FieldSchema(
name="publish_year",
data_type=zvec.DataType.INT32,
),
],
vectors=[
zvec.VectorSchema(
name="embedding",
data_type=zvec.DataType.VECTOR_FP32,
dimension=768,
index_param=zvec.HnswIndexParam(metric_type=zvec.MetricType.COSINE),
),
],
)
# 创建并打开集合
collection = zvec.create_and_open(
path="./my_collection_data",
schema=schema,
)
3. 插入数据
collection.insert(
zvec.Doc(
id="book_1",
vectors={"embedding": [0.1] * 768}, # 替换为实际向量
fields={"publish_year": 1936},
)
)
# 构建索引(新插入的向量需要优化后才能快速搜索)
collection.optimize()
4. 向量搜索
result = collection.query(
queries=zvec.Query(
field_name="embedding",
vector=[0.3] * 768, # 替换为实际查询向量
),
topk=10,
)
print(result)
5. 带条件过滤的搜索
result = collection.query(
queries=zvec.Query(
field_name="embedding",
vector=[0.3] * 768,
),
topk=10,
filter="publish_year > 1936",
)
print(result)
更多操作:按 ID 查、按条件删,全套 CRUD 都有。
Zvec 是什么?
Zvec 是一个运行在你程序内部的向量数据库,不是独立的服务进程。你 pip install zvec,打开一个集合目录,插入向量,就能查。无服务器、无端口、无连接池。类比:SQLite 之于 Postgres,Zvec 之于 Milvus。
阿里巴巴内部已将其用于多个生产场景,开源前就经过了严格的实战检验。
v0.5.0 核心更新
- 全文搜索(FTS):对任意字符串字段附加 FTS 索引,支持自然语言查询,无需外部搜索引擎
- 混合检索:在同一查询里融合稠密向量 + 稀疏向量 + 标量过滤 + 全文搜索
- DiskANN 索引:磁盘索引大幅降低内存占用,适合海量数据集
- 新 SDK:Go、Rust 官方绑定,以及 Zvec Studio 可视化工具
- RISC-V 支持
为什么重要?
现有的向量数据库(Qdrant、Weaviate、Milvus、Chroma server 模式)都需要额外跑一个进程。如果你只是想本地做向量搜索、RAG、语义匹配,部署一个服务太重了。
Zvec 的方案是:pip install 就完事了。像这样:
import zvec
schema = zvec.CollectionSchema(
name='example',
vectors=zvec.VectorSchema('embedding', zvec.DataType.VECTOR_FP32, 4),
)
collection = zvec.create_and_open(path='./zvec_example', schema=schema)
collection.insert([
zvec.Doc(id='doc_1', vectors={'embedding': [0.1, 0.2, 0.3, 0.4]}),
zvec.Doc(id='doc_2', vectors={'embedding': [0.2, 0.3, 0.4, 0.1]}),
])
results = collection.query(
zvec.VectorQuery('embedding', vector=[0.4, 0.3, 0.3, 0.1]),
topk=10
)
print(results)
性能也很能打:Cohere 1000 万向量数据集上,索引构建约 1 小时,查询达 8500+ QPS。
适合买手/电商场景
跟你在做的 maishou 方向强相关:
- 商品相似度匹配:嵌入本地,不用搭服务
- 选品分析:基于向量语义快速找同类商品
- 评论语义分析:RAG 给商品评价做智能问答
- 以图搜图:图片 embedding 后直接检索
技术要点
- WAL 持久化:写前日志保证数据不丢失,进程崩溃也不怕
- 多进程并发读:同一集合多进程读,写独占
- 跨平台:Linux/macOS/Windows 都支持,x86_64 和 ARM64
- 多语言 SDK:Python、Node.js、Go、Rust、Dart/Flutter
一句话总结
如果你需要一个 跑在程序内部、不需要部署服务、pip 即用 的向量数据库,Zvec 是目前最优雅的选择。阿里出品,Apache 2.0 开源,值得关注。
GitHub: https://github.com/alibaba/zvec
官方文档: https://zvec.org/en
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END









cqlbgzs@163.com 1年前0
d好879445037@qq.com 2年前0
购买了 无法下载Alexcc 3年前0
强大Alexcc 3年前0
看不了教程Alexcc 3年前0
雷刺下载Alexcc 3年前0
下载Alexcc 3年前0
下载dsa456159 3年前0
下载