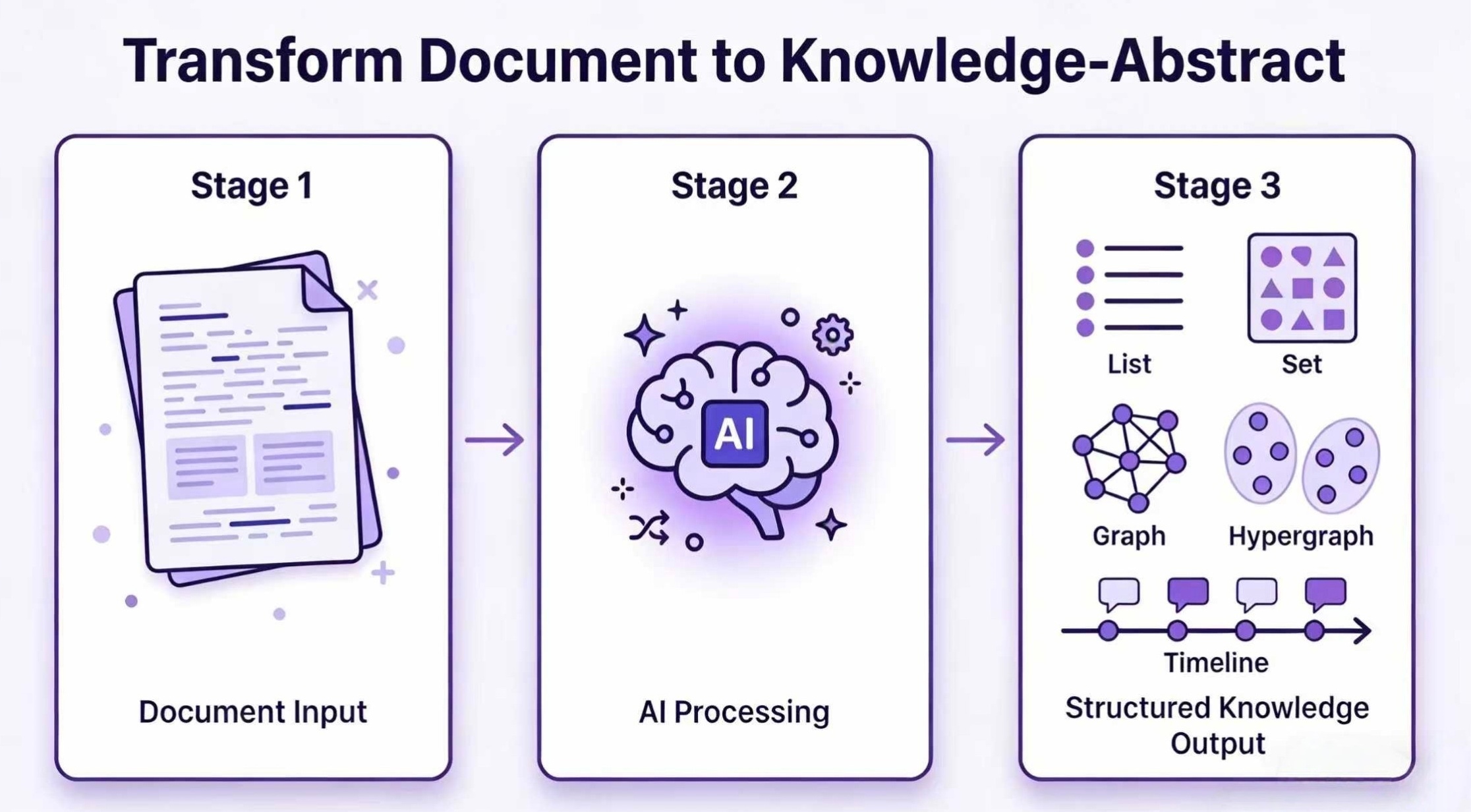

项目概述
Hyper-Extract 是一个基于大语言模型(LLM)的智能知识提取与演化框架,由 yifanfeng97 开发并开源。它的核心理念是”告别文档焦虑,让信息一目了然”——只需要一条命令,就能把长篇大论的非结构化文本(论文、财报、法律合同、行业报告等)自动转换为结构化、可查询、可演化的知识摘要。
项目在 GitHub 上发布后迅速获得 1700+ Star,足见社区对”文档结构化”这个痛点的共鸣。更重要的是,它支持完全本地化部署,数据不会离开你的机器,对隐私敏感的用户非常友好。
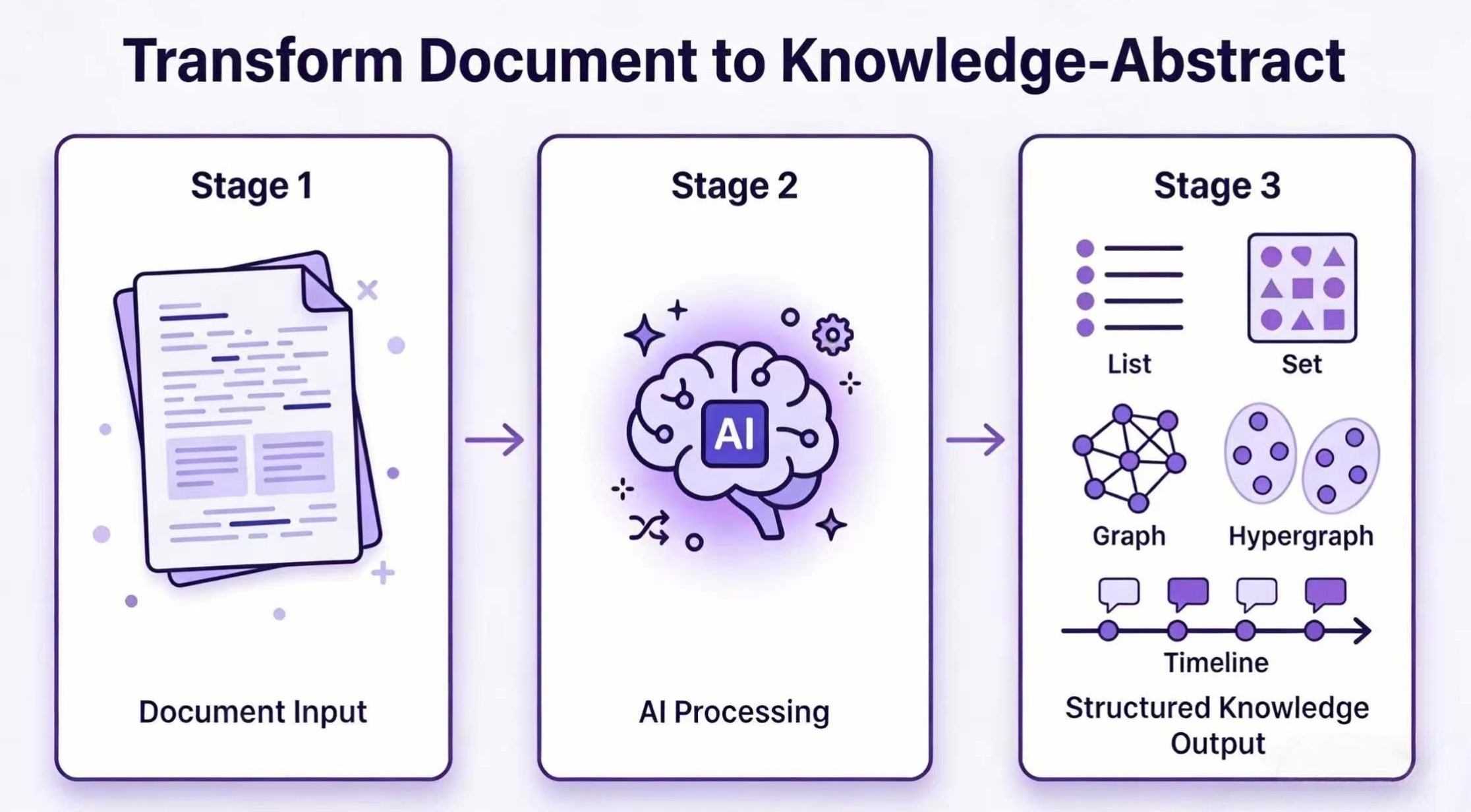
核心特性
- 8 种知识结构:从简单的列表(List/Set),到 Pydantic 模型,再到知识图谱(Knowledge Graph)、超图(Hypergraph),甚至时空图(Spatio-Temporal Graph),覆盖各种场景。
- 10+ 提取引擎:内置 GraphRAG、LightRAG、Hyper-RAG、KG-Gen 等多种主流提取算法,开箱即用。
- 80+ YAML 模板:覆盖金融、法律、医疗、中医、工业、通用等领域,零代码配置就能用。
- 增量式演化:可以不断喂入新文档,知识库会自动增补和优化,不需要从头再来。
- 交互式 CLI:提取后可以直接在终端里搜索、可视化查询结果。
- 多种 LLM 支持:兼容 OpenAI(GPT-4o/GPT-5)、阿里云百炼(Qwen-Plus / DeepSeek-R1),以及本地部署的 vLLM。
- 完全本地化:通过 vLLM 部署本地模型,数据不需要上传到任何第三方服务。
安装步骤
Hyper-Extract 推荐使用 uv(Python 包管理器)安装,干净又简单。如果你没有 uv,也可以直接用 pip。
方法一:使用 uv(推荐)
# 安装 Hyper-Extract
uv tool install hyperextract
# 配置你的 API Key(以 OpenAI 为例)
he config init -k YOUR_OPENAI_API_KEY方法二:使用 pip
pip install hyperextract安装完成后,你就拥有 he 这个命令行工具了。
使用示例
1. 从文档中提取知识图谱
假设你有一篇特斯拉的传记文档 tesla.md,想从中提取人物、事件及关系:
# 提取知识图谱
he parse tesla.md -t general/biography_graph -o ./output/ -l en
# 查询提取结果
he search ./output/ "特斯拉的主要成就有哪些?"
# 可视化查看
he show ./output/就这么简单。几条命令下去,一篇几十页的文档就变成了可视化、可搜索的知识图谱。
2. 金融财报分析
he parse earnings.md -t finance/earnings_graph -o ./finance_kb/
he search ./finance_kb/ "主要风险因素有哪些?"3. 本地化部署(数据不出门)
如果你对隐私要求极高,可以用 vLLM 跑本地模型:
from hyperextract import create_client
llm, emb = create_client(
llm="vllm:Qwen3.5-9B@http://localhost:8000/v1",
embedder="vllm:bge-m3@http://localhost:8001/v1",
api_key="dummy",
)适用场景
- 研究人员:将 20 页的论文转化为概念、作者、引用关系图
- 金融分析师:从财报中自动识别公司、高管、财务指标及关系
- 法务工作者:从合同中抽取条款、义务、时间节点
- 产品经理/买手:从竞品分析报告、用户评论中提取产品特征和用户需求,形成结构化洞察
- 任何需要梳理大量文本的人
结语
Hyper-Extract 的价值在于它把”读懂文档”这件事交给了 AI,让人只需要关注”问什么问题”。它强大的模板系统、丰富的提取引擎、以及增量式知识演化能力,让它在同类工具中脱颖而出。无论你是 AI 从业者还是日常需要处理大量文档的用户,都值得一试。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END









cqlbgzs@163.com 1年前0
d好879445037@qq.com 2年前0
购买了 无法下载Alexcc 3年前0
强大Alexcc 3年前0
看不了教程Alexcc 3年前0
雷刺下载Alexcc 3年前0
下载Alexcc 3年前0
下载dsa456159 3年前0
下载